


There is a lot of hype around artificial intelligence (AI) and what it can currently do, but for most applications we are still in the early days of AI. This doesn’t mean we aren’t seeing some impressive results from these early efforts however. For example, Sterblue was recently able to deliver high-quality results using their AI to conduct power grid inspections, which they outlined in an in-depth blogpost on their site.
In order to find out more about their AI solution, Commercial UAV News spoke with Sterblue’s CEO, Geoffrey Vancassel; CTO, Vincent Lecrubier; and Ouail Bendidi, Data Scientist. During our conversation, we discussed how they developed and tested their AI and the metrics they used for evaluting its success, what it takes to train an AI and get results that are accurate and explainable, how all of this is making a difference in infrastructure inspections, and more.
Danielle Gagne: Can you tell us a little bit about Sterblue and how it got into machine learning and AI?
Geoffrey Vancassel: At Sterblue we build the central platform for infrastructure inspections. We build the tools to capture clean data from multiple sources like drones, smartphones, helicopters or satellite. Based on that, we model disparate customer processes to organize data with one standard model. We build the interfaces and tools to provide insightful analytics. And finally, we are transforming the industry with our API. We have started with drone imagery and energy applications.
Artificial Intelligence (AI) is a tool at the middle of our streamlined workflow. We have built these dedicated tools (depending on the assets) to accelerate infrastructure analysis on our platform and support business domain knowledge experts delivering faster and better reporting.
You recently utilized machine learning to conduct power grid inspections, can you tell us a bit about that project and how drones were able to facilitate it?
Vancassel: We have been working with almost 15 different utilities to automate their defect or equipment detection. These projects always start by understanding the customer’s operational expectations, AI for what? Real power grids only have a few small differences from one country/region to the next, but condition monitoring/asset management policy can change a lot from one customer to another. Our work within the first days with a new customer is to make sure we can model its business domain knowledge and integrate seamlessly within its workflow. Automating defect or equipment detection with AI is then a natural step. Drones facilitate AI deployment because of the highly structured data collection made possible.
In your blogpost about AI data collection you talk about “the clichés of AI as a magical tool that will solve all problems with a single click.” How do you think some of that hype came about and what are some actual AI-enhanced applications that can/do happen today?
Vancassel: First these two words make it magic “Artificial” and “Intelligence”, who would not have amazing expectations when saying them! But more seriously we have seen a lot of players on the market (and still today) putting some box/labels on pictures, sharing it on social media and promising some outstanding capabilities to detect defects really easily. That’s normal, this is visual and easy to promote. In real life, holding such a promise is possible but this is a long, demanding and highly structured journey in order to reach production-level performances. We have different use cases that demonstrate this level of performance, for example we are capable of detecting seven different equipment of distribution grids, and we can prove it.

In that same post, you talk about needing to gather a lot of high-accuracy data in order to train the neural network to recognize and process datasets. Can you talk about what kind of work went into this process of training that neural network and how drones are enabling you to gather that data faster, cheaper, and more accurately than with traditional manual processes of data collection?
Ouail Bendidi: High-quality data is a must for any data-driven approach, especially for training neural networks since they learn directly from it. As we can expect, a subpar learning material inevitably leads to subpar training results.
To get high-quality data, the most common approach is to get as much data as possible then do successive rounds of cleaning until we get to the desired quality. This approach is both inefficient and not scalable. Our solution at Sterblue is to tackle the problem from the source—during its data capture—if we can control and automate (to minimize human error) the data acquisition, we are sure to always and consistently get data that fit our standards.
Drones proved to be one of the best options for automatic data acquisition. Thanks to our automatic flight software, images are captured in a standard way, independently from the location or the pilot, before being ingested in our cloud for further automatic selection and labeling.
Thanks to that, we switched our focus from the never-ending process of data cleaning, and we are able to focus more on perfecting our AI models to achieve human-level accuracy.
We often talk about this concept of “garbage in, garbage out” when it comes to data collection and processing and that is definitely an issue, but with AI the data input could be excellent but that data has to be translated through an artificial neural network—how that AI interprets that data matters. As you state, a few amazing results in a sea of garbage doesn’t mean your AI knows what it is doing. What are the metrics for determining when your AI system is producing high-quality results?
Vincent Lecrubier: Indeed, ensuring that the AI provides useful results is key to the successful adoption of this tool. To do this, the two main metrics we monitor are Precision and Recall.
Recall is the ratio of real-life defects that are successfully detected by the AI. If there are 100 real-life defects and the AI correctly detects 90 of these defects and misses 10 of them, then the recall is 90%. This is often the most important metric for critical infrastructure where we want to ensure that we miss almost no real defect.
Precision is the ratio of detected defects that are actual defects. If the AI detects 100 defects and 70 of them are real-life defects and 30 of them are not really defects, then the precision is 70%. This is the second metric that we want to optimize, as we don’t want to overwhelm our users with false alerts.
These two metrics are measured by having the AI go through a set of images, and then having several humans go through the same images to build what is called the ground truth: What is believed to be the correct result. It is important to have several humans to build the ground truth because humans themselves are not perfect. We then compare the ground truth to the AI results and compute precision and recall.
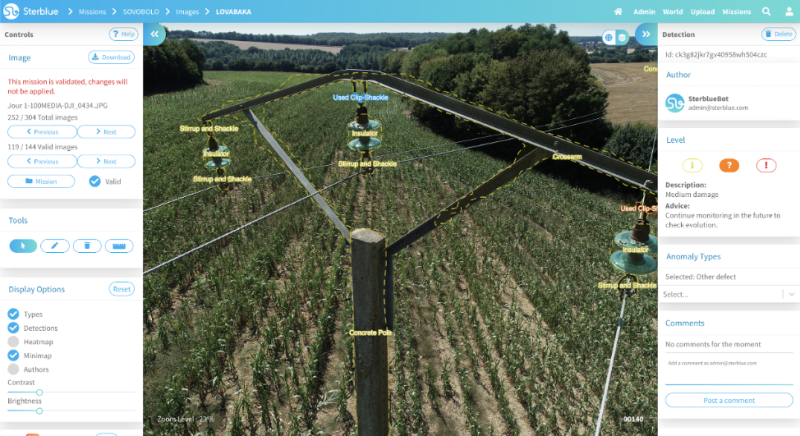
You talk about being able to reach a human-level of analysis in your blog—How did you define what a human level of ability was and how were you able to quantify and qualify that definition from the results you were getting?
Bendidi: As mentioned, to assess either an AI or human level of expertise we use two metrics widely used in the AI community: recall and precision.
The evaluation process is straightforward, we evaluate on a set of test data (new data that were never seen by either the AI or the human expert), and then compare results with the validated ground-truths to calculate the recall and precision.
By observing the results, we noticed that on some tasks the AI was able to get comparable recall and precision to a human, and by steadily increasing the test dataset size, the human recall started to slowly decrease (caused by numerous factors, such as tiredness, duplication, human error, and so on) while the AI remained relatively consistent in its results.
The goal of our AI is not to replace the human expert but to augment him/her, to give him/her the needed tools to make his/her job faster and more accurate.
You talk about switching to a third-party data labeling provider to help you with AI training. Can you talk a little bit more about where you were getting the labeled data before and who was doing it, why you made the choice to work with a third-party, and how that impacted your end result?
Lecrubier: There are three steps in the process of training a performant AI at this scale.
First, we start at a small scale, by having our customers label images on our platform by themselves. This is a very good way to agree on a common anomaly referential: Real-life examples are the best way to communicate what is a defect and what is not, and what classes of defect we are interested in. However, AIs need quite a lot of good quality data to get really good at their job. Asking our customers to do all of this high precision labeling is not ideal on both sides: Our customers are rarely able or willing to provide sufficiently high data quality or quantity.
So, there comes the second stage: As the dataset reaches a medium scale, we use third-party human labeling providers. They start from the referential and examples provided by customers and then take over the labeling of larger datasets. Their position as third parties means that our incentives align, and we contractually agree with them to provide high-quality data and pay them for that.
Finally, on a large scale, we reach the third stage, which is automatic labeling by the AI, with only marginal human intervention. At this point we use a mix of third-party and customer validation of the findings.
Each stakeholder has a role in this three-stage process, which has to be repeated for each class of anomaly that we want to detect automatically. Our role is to streamline and coordinate this whole process to ensure useful insights for our customers in the end.
There are a lot of AI solutions being advertised out there, especially in the inspection space, and not all are created equally. If I am an end user looking for a high-quality solution, what are some ways I can determine whether the AI solution being provided is going to give me the results I am looking for and need?
Bendidi: One of the easiest ways to decide whether an AI solution is worth it or not is by checking the amount of data the company has or can have access to. The AI solutions used by Google or Facebook are successful mostly because of the huge data that they have. In the inspection space, for example, an AI that was trained on data from different countries will be able to generalize better than an AI that has seen only a single type of infrastructure.
Another important factor to check for is the potential of the AI to improve, a solution with an end-to-end pipeline from data acquisition to having the AI in production will allow for constant and incremental improvement as more inspections are done.
And of course, making sure that there is a qualified team working on the AI!












Comments